# 函数式编程学习
本文主要记录学习函数式编程学习时的知识点,存在博主知识范围能力有限,文章内容存在用词不当或者说法错误的地方,望指出。
本文主要从以下方面来阐述:
- 函数
- 闭包
- 组件
- 不变性:何管理值和状态的变化,状态变化的管理是所有编程的关键理念之一。这是状态管理机制。
- 递归
- 链表/数据结构
- 异步
- 函数式编程函数库
# 函数的纯净
函数式编程并不只是关于函数关键字。在程序中使用函数关键字,并不意味着在进行函数式编程。
例如:
function addNumbers(x = 0, y = 0, z = 0, w = 0) {
let total = x + y + z + w;
console.log(total);
}
function extraNumbers(x = 2, ...args) {
return addNumbers(x, 40, ...args);
}
extraNumbers(); // 42
extraNumbers(3, 8, 11); // 62
2
3
4
5
6
7
8
9
10
11
上述代码并不是函数,而是一个过程,所谓过程就是操作的集合,是你在程序中需要做的事情的集合。它只是使用了函数关键字,并且接受了输入,并将结果打印在了控制台。即命令式编程(Imperative Programming)与之相对的则是声明式编程(Declarative Programming)。
因此我们需要了解函数是什么?首先函数不仅需要输入,同样需要输出,而不是在控制台中进行输出,即它必须有返回,即 return 关键字。(任何没有 return 关键字的都是过程)
函数可以调用过程,从而自身也会变成过程,因此 extraNumbers 也是一个过程,因此他不能用于函数式编程。有些类似函数 api 的东西,看起来是函数模式,但实际上并不是真正的函数。他没有真正的功能。
而下面的例子就是一个函数:
function tuple(x, y) {
return [x + 1, y - 1];
}
var [a, b] = tuple(...[5, 10]);
a; // 6
b; // 9
2
3
4
5
6
7
Function: the semantic relationship between input and computed output
**函数并不仅仅是输入和输出,其本质是输入和计算输出之间的语义关系。**而不仅仅是接收一个数值然后返回一个数值。如计算费率的函数,函数名称将说明语义关系。如果我输入尺寸、重量和速度,就会得到运费率。这就是它的作用。
function shippingRate(size, weight, speed) {
return ((size + 1) * weight) + speed;
}
2
3
同时没有输入是一个有效输入,但是输入和输出之间有语义关系吗?同时, undefined 是一个有效的输出,只要其和输入有语义关系。如果一个函数的作用就是获取一个对象的属性,如果这个对象没有此属性,正确的语义就是返回没有定义,这与函数式编程完全一致,要有明显的语义关系。
In functional programming for there to be a function, it's got to not have side effects.
函数式编程中的函数必须没有副作用。
这里的副作用包括两个方面:
- 间接的输入
- 潜在的间接的输出
直接且确定的输入,必须计算并返回一个值,而不需要赋值给其自身以外的的东西。它不能访问外部的任何东西也不能分配给外部的任何东西。这是一种明确而可靠的方法来避免所有的副作用。
同时在 JavaScript 重要的是函数调用时的直接输入。因此如果可能的话我们在函数调用的时候应该避免副作用。

其中任何运行的程序都会通过CPU产生热量,这是一个副作用,可以观察到系统状态的变化。事实上,不仅仅是CPU的热量,一个程序不能运行的时间延迟是因为另一个程序正在运行,这是一个副作用。
**因此在实践中我们并不能避免所有的副作用,只能尽可能的减少副作用。**我们可以将带有副作用的函数单独存放于一个文件中,便于测试。
所谓纯函数是指纯函数调用,因为 JavaScript 并不是严格意义上的函数式语言。这个函数具有直接的输入和输出,并且不会产生任何副作用。
如果函数内部要调用函数外部的变量,一般会使用 const 关键字来声明变量,从而说明这个值是不变的的,如下所示:
const z = 1;
// var z = 1;
function addTwo(x, y) {
return x + y;
}
function addAnother(x, y) {
return addTwo(x, y) + z;
}
console.log(addAnother(20, 21)); // 42
2
3
4
5
6
7
8
9
10
11
但实际重要的是变量是否被重新赋值,而不是能否重新赋值。因此其实这里使用 var 和 const 关键字的作用是一样的,只要没有重新给变量赋值,就如同 addAnother 函数中引用了没有重新分配的 addTwo 函数一样。因此,上述两个函数都是纯函数。
reducing surface area,以下例子增加了可读性,当传递一个参数时,返回的函数进行调用时,它实际上相当于一个常数,因此下面的函数也可以视为纯函数。
function addAnother(z) {
return function addTwo(x, y) {
return x + y + z;
}
}
console.log(addAnother(1)(20, 21)); // 42
2
3
4
5
6
7
**同时纯净的函数需满足同样的参数,返回同样的结果。**以下函数就不是纯函数,因为同样的参数,返回的结果不同。
function getId(obj) {
return obj.id;
}
getId({
get id() {
return Math.random();
}
});
2
3
4
5
6
7
8
如何编写纯函数,应尽可能提取出不纯的函数,保留纯函数,而不是将其隐藏在过程中。
如果不能提取出不纯的函数,那么就需要**包含不纯的函数,**从而不会影响应用的其他部分。
- using wrapper function: an impure function wrapped around a pure function. the side effects that occur are not in the global scope, but they are inside of a function scope.
- using adapter function: capture a current state so the state can be restored later. It's worse than first, but better than nothing. Remember the six steps that you basically need to accomplish. You need to save the current state, set up the appropriate initial state, call the side effect, capture the new state, restore the old state and then return the captured state.
// 初始具有副作用的不纯函数
var someApi = {
threshold: 13,
isBelowThreshold(x) {
return x <= someApi.threshold;
}
}
var numbers = [];
function insertSortedDesc(v) {
someApi.threshold = v;
console.log(someApi.isBelowThreshold);
var idx = numbers.findIndex(someApi.isBelowThreshold);
if (idx == -1) {
idx = numbers.length;
}
numbers.splice(idx, 0, v);
}
insertSortedDesc(3);
insertSortedDesc(5);
insertSortedDesc(1);
insertSortedDesc(4);
insertSortedDesc(2);
numbers; // [5,4,3,2,1]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
通过包含函数,将不纯的函数包含起来,减少副作用。
var someApi = {
threshold: 13,
isBelowThreshold(x) {
return x <= someApi.threshold;
}
}
var numbers = [];
function getSortNums(nums, v) {
var numbers = nums.slice();
insertSortedDesc(v);
return numbers;
function insertSortedDesc(v) {
someApi.threshold = v;
console.log(someApi.isBelowThreshold);
var idx = numbers.findIndex(someApi.isBelowThreshold);
if (idx == -1) {
idx = numbers.length;
}
numbers.splice(idx, 0, v);
}
}
numbers = getSortNums(numbers, 3);
numbers = getSortNums(numbers, 5);
numbers = getSortNums(numbers, 1);
numbers = getSortNums(numbers, 4);
numbers = getSortNums(numbers, 2);
numbers; // [5,4,3,2,1]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
注意这里我们使用了使用了 wrapper function ,从而使得不会直接修改全局数组,而是局部数组。但是注意这里我们还是直接修改了 someApi 中的数据,这里我们认为其是第三方库提供的函数,那么它可能在一个单独的文件中,从而无法使用 wrapper function,因此需要我们使用 adapter function。
var someApi = {
threshold: 13,
isBelowThreshold(x) {
return x <= someApi.threshold;
}
}
var numbers = [];
function insertSortedDesc(v) {
someApi.threshold = v;
console.log(someApi.isBelowThreshold);
var idx = numbers.findIndex(someApi.isBelowThreshold);
if (idx == -1) {
idx = numbers.length;
}
numbers.splice(idx, 0, v);
}
function getSortNums(nums, v) {
var [origNumbers, origThreshold] = [numbers, someApi.threshold];
numbers = nums.slice();
insertSortedDesc(v);
nums = numbers;
[numbers, someApi.threshold] = [origNumbers, origThreshold];
return nums;
}
numbers = getSortNums(numbers, 3);
numbers = getSortNums(numbers, 5);
numbers = getSortNums(numbers, 1);
numbers = getSortNums(numbers, 4);
numbers = getSortNums(numbers, 2);
numbers; // [5,4,3,2,1]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
上述方法使得最后调用的时候,并不会改变程序状态的任何其他东西,他并不依赖于项目的状态。
如果我们通过上述几种方法都不能使其成为纯函数调用,那么就尽可能的让副作用变得明显,从而更易维护。
# 参数适配
函数式程序员倾向于使用一元函数,即单输入,单输出。其次是二元函数,两个输入,一个输出。单门占据着函数式编程的大部分函数。函数的输入参数越多,越难与其他函数进行协同协作。
// unary
function increment(x) {
return sum(x, 1);
}
// binary
function sum(x, y) {
return x + y;
}
2
3
4
5
6
7
8
9
higher order function ( HOF ): higher-order function is a function that either receives, as its inputs. One or more functions, and/or returns one or more functions.
我们可以通过高阶函数来适配自己想要的一元或者二元函数,如下面的函数所示:
function unary(fn) {
return function one(arg) {
return fn(arg);
}
}
function binary(fn) {
return function two(arg1, arg2) {
return fn(arg1, arg2);
}
}
function f(...args) {
return args;
}
var g = unary(f);
var h = binary(f);
console.log(g(1, 2, 3, 4)); //[1]
console.log(h(1, 2, 3, 4)); //[1,2]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
让我们来看看其他的适配器,如果我们几个二元函数有时候接收的参数顺序为 x 和 y,有的时候为 y 和 x。那么 filp 函数就是用来实现此功能的,他可以接收任意多的参数,但是只转换前两个参数的顺序。
function filp(fn) {
return function filpped(arg1, arg2, ...args) {
return fn(arg2, arg1, ...args);
}
}
function f(...args) {
return args;
}
var g = filp(f);
console.log(g(1, 2, 3, 4)); // [2,1,3,4]
2
3
4
5
6
7
8
9
10
11
12
同理下面转换参数的顺序函数也是如此:
function reverseArgs(fn) {
return function reversed(...args) {
return fn(...args.reverse());
}
}
function f(...args) {
return args;
}
var g = reverseArgs(f);
console.log(g(1, 2, 3, 4)); // [ 4, 3, 2, 1 ]
2
3
4
5
6
7
8
9
10
11
12
上面是适配器的例子。通过例子可知,当你发现函数的“形状”不合适。可以通过以下两种方式来寻找共同模式,从而可以保证它们如同乐高玩具一样拥有相同的接口,可以相互连接在一起。:
- 可以在函数定义时改变函数的“形状”么?
- 如果没有,我可以做一个适配器来改变“形状”吗?
# Point-free
Point 实际上是指函数的参数,在数学术语中,它被称之为点,Point-free 是一种编程风格,是一种不需要在函数内部编写任何内容的函数定义方式,是一种通过其他函数生成新的函数的编程方式。
它更像一种声明式的编程方式,在函数定义时将参数的转换过程隐藏了,其实当你去问别的程序员代码是显式的好还是隐式的好,可能大多数程序员都会告诉你显式的好,因为那可以让你知道代码里面发生了什么。但是在有的情况下代码可以是隐式的,比如在函数式编程中,那些一个个的“函数组件”能够使我们充分处理好我们的输入输出,我们只需要关注在最后的输出是不是我们想要的,不用去关注它是怎么去做转换的,因为这对于阅读代码的人来说并不是一个非常重要的细节。
函数式推理
函数式推理是关于这个函数的推理,方程式上并不相等,但是在函数“形状”上是相等的。
getPerson(function onePerson(person) {
return renderPerson(person);
});
getPerson(renderPerson);
2
3
4
5
可读性
function isOdd(v) {
return v % 2 == 1;
}
function isEven(v) {
return !isOdd(v);
}
console.log(isEven(4)); // true
2
3
4
5
6
7
8
9
在上面我们当然可以将 isEven 的定义写成 return v % 2 === 0 ,但其实这增加了代码的理解过程。上面的方法将两者函数之间建立了一个更明显的相反关系,从而提升了代码的可读性。你可能会说这违背了 DRY ( don't repeat yourself ) 观点,但实际上,有时候在函数式编程中,最好是重复。
现在让我们将上述代码重构成 point-free 风格,首先将参数传递隐藏,同时一眼看到代码就能意识到 isEven 是 isOdd 的否定形式。
function not(fn) {
return function negated(...args) {
return !fn(...args);
}
}
function isOdd(v) {
return v % 2 == 1;
}
var isEven = not(isOdd);
console.log(isEven(4)); // true
2
3
4
5
6
7
8
9
10
11
12
13
其中 not 函数在 Ramda 函数库中就是 complement 函数。point-free 风格的代码首要的事情就是为函数起一个通俗易懂的名称,从而起到望文知义,还原函数式编程的初衷。
Point-free 高级应用
point-free 的应用不仅仅是用来利用原有的函数来组合新的函数,我们还可以通过使用一些函数的“通用组件”来组成所需要的“特殊组件”。我们还是以上述的例子为例:
function mod(y) {
return function forX(x) {
return x % y;
}
}
function eq(y) {
return function forX(x) {
return x === y;
}
}
2
3
4
5
6
7
8
9
10
11
加入我们有两个函数,一个是返回 x 对 y 的取余结果,一个是判断 x 是否与 y 相等。他们都有两个重要的特点:
- 接收参数的顺序都是反直觉的,但是在函数式编程中这些却是必须的。
- 他们虽然都不是一元函数,但是经过柯里化处理,是由两个一元函数”嵌套“而成,这点在函数式编程中也极为重要,这使得两个函数具有相同的接口,从而可以很好的连接在一起。
然后我们用这两个函数来定义之前的 isOdd 函数:
var mod2 = mod(2);
var eq1 = eq(1);
function isOdd(x) {
return eq1(mod2(x));
}
2
3
4
5
6
我们先给 mod 和 eq 两个函数传递一个参数,从而使其成为一个特殊化的参数,这样在通过结合可以获得 isOdd 函数。这时函数的定义已经从命令式慢慢过度到了声明式,但是还没有达到 point-free 的编码风格。这样在一个函数调用后的输出成为下一个函数的参数的方法,在数学上称之为 Composition 。即文章开头的 composition 。
通过函数式推理( equational reasoning)可以编写 compose 函数:
var mod2 = mod(2);
var eq1 = eq(1);
function isOdd(x) {
return eq1(mod2(x));
}
function compose(fn2, fn1) {
return function composed(v) {
return fn2(fn1(v));
}
}
var isOdd = compose(eq1, mod2);
var isOdd = compose(eq(1), mod(2));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
有些人觉得这里compose 函数的参数是反直觉的,这是因为人们通常习惯从左到右进行阅读,但其实这里的运行顺序是从右到左的。这当然是有原因的:
- 我们回到之前提到的
eq和mod函数中的第一个重要特点 — 参数顺序,我们假如他们的参数顺序是符合人类直觉的,那么他们就不可能像我们最终定义哪样进行定义; - 当然你也可以说,我可以改变compose函数的定义来让他们可以组合在一起呀。这就是我第二个原因,在数学中函数复合写作
fog(相当于compose(f, g)),意思是一个函数接收一个参数x,并返回一个f(g(x))。
# 闭包
如果你不理解闭包,那么你无法进行函数式编程。
Closure is when a function remembers the variables around it even when that function is executed elsewhere.
简单来说闭包就是可以访问另一个函数的变量。它是一种保护私有变量的机制,在函数执行时形成私有的作用域,保护里面的私有变量不受外界干扰,直观来说就是形成一个不销毁的栈环境。
可以见以下闭包函数的例子:
function makeCounter() {
var counter = 0;
return function increment(){
return ++counter;
}
}
var c = makeCounter();
console.log(c()); // 1
console.log(c()); // 2
console.log(c()); // 3
2
3
4
5
6
7
8
9
10
11
由于上述函数在每次同样的输入都会得到不同的输出,因此上述函数并不是纯函数。因此我们可以得出以下结论:闭包不一定是纯函数。但是闭包一定可以用于函数式编程的理论中。
如以下闭包函数就相当于一个纯函数:
function unary(fn) {
return function one(arg) {
return fn(arg);
};
}
function sum(z) {
return function addTwo(x, y) {
return x + y + z;
};
}
2
3
4
5
6
7
8
9
10
11
延迟执行还是快速执行
让我们来看看这个函数:
function repeater(count) {
return function allTheAs() {
return ''.padStart(count, 'A');
}
}
var A = repeater(10);
console.log(A()); // AAAAAAAAAA
console.log(A()); // AAAAAAAAAA
2
3
4
5
6
7
8
9
上面这个函数是在最后调用 A 时才生成字符串,这就是延迟执行,只有在函数调用之后才会得到正确结果,这适用于一个函数调用非常少的次数时,不会对资源造成严重的浪费。我们来看下一个快速执行的例子:
function repeater(count) {
var str = ''.padStart(count, 'A')
return function allTheAs() {
return str;
}
}
var A = repeater(10);
console.log(A()); // AAAAAAAAAA
console.log(A()); // AAAAAAAAAA
2
3
4
5
6
7
8
9
10
这就是快速执行,在函数调用之前我们就已经得到了结果,一次调用,可以多次使用数据。
记忆化
因此为了代码能够延迟执行,且只有一次调用,除非是再次重新请求。因此我们需要编写一个折中的函数:
function repeater(count) {
var str;
return function allTheAs() {
if (str == undefined) {
str = ''.padStart(count, 'A')
}
return str;
}
}
var A = repeater(10);
console.log(A()); // AAAAAAAAAA
console.log(A()); // AAAAAAAAAA
2
3
4
5
6
7
8
9
10
11
12
13
虽然上面的函数同样的输入,输出的结果相同,但是他改变了 str 变量,因此这个并不是纯函数,那么就需要一个适配函数,用来维护内部的缓存,从而编写出更具声明式的函数:
function repeater(count) {
return memorize(function allTheAs() {
return ''.padStart(count, 'A');
})
}
var A = repeater(10);
console.log(A()); // AAAAAAAAAA
console.log(A()); // AAAAAAAAAA
2
3
4
5
6
7
8
9
这个适用于期望多次相同的输入调用。否则它将会占用很多内存。
引用透明
如果一个函数调用具有引用透明性,那么它就是纯函数调用。引用透明意味着,一个函数调用可以用它的返回值替换,而不会影响程序的任何其他部分。
为了让读者(包括未来的自己)能够尽可能轻松地查看一行代码,并准确地知道它要做什么,而不必一遍又一遍地重复去浏览代码。
只有明白了纯函数调用的价值和重要性,你才能从函数式编程中受益。
从广义函数到特定函数
这里我们编写一个 AJAX 函数,它接收三个参数,一个 url ,一个数据参数,然后是一个回调函数:
function ajax(url, data, cb) {
/*..*/
}
ajax(CUSTOM_API, {
id: 2
}, renderCustomer);
2
3
4
5
6
7
但是对于阅读代码的人来说,可能其中的一些细节并不是必要的,而不是阅读一长串数据参数。因此我们需要一些中间步骤,将这些不必要的细节隐藏起来,从而是读者理解代码的更加清除。所以我们编写了 getCustomer 函数,他已经明确的知道了调用 ajax 函数的 url 地址,因此只需要接收后面两个参数即可:
function getCustomer(data, cb) {
return ajax(CUSTOM_API, data, cb);
}
getCustomer({
id: 2
}, renderCustomer);
2
3
4
5
6
7
可能我们看到过某些文章上面说只有在使用过三次及以上,我们就可以将其编写成函数或者程序,但是你要知道将代码抽象成函数,是为了使代码更加的语义化,更加的易于理解,函数的名称就描述了代码的用途。
因此,可能在某些时候我们不仅需要获取客户,更要获取一些特定的客户,如获取当前的客户,因此我们可以将代码再次更加具体化:
function getCurrentUser(cb) {
// return ajax(CUSTOM_API, { id: 2 }, cb);
return getCustomer({
id: 2
}, cb);
}
getCurrentUser(renderCustomer);
2
3
4
5
6
7
8
这里我们内部使用的是 getCustomer 函数而不是 ajax 函数,这是因为 getCurrentUser 函数是 getCustomer 函数的特定化,而不是 ajax 函数的特定化函数,因此选用前一种会将函数之间的关系体现的更加明显。
但定义上述函数也可能会使代码看起来很乱,因此我们需要一些方法来定义更加专门化的函数,而不是这样一个个的手动定义。为了解决这个问题,我们就要了解到参数的顺序是至关重要的。当我们设计一个函数时,参数的顺序应该是从一般到特殊的。就像 map 函数,它接收两个参数,一个是数组,一个是函数,通常我们习惯第一个参数是数组,但是每个函数库中基本上都是函数是第一个参数,因为回调对于输入来说更加通用,而数组是更加具体也就是特殊的参数。
偏函数和柯里化(Partial Application & Currying)
对于上面的 ajax 函数,有两种方式来使其专门化,其中一个就是 partial application ( 偏函数 ),来看下面一个例子:
function ajax(url, data, cb) {
/*..*/
}
var getCustomer = partial(ajax, CUSTOMER_API);
// var getCurrentUser = partial(ajax, CUSTOMER_API, { is: 2 });
var getCurrentUser = partial(getCustomer, {
id: 2
});
getCustomer({
id: 2
}, renderCustomer);
getCurrentUser(renderCustomer);
2
3
4
5
6
7
8
9
10
11
12
13
14
其中每个函数库里面都会有 partial 这个函数,它把一个函数作为它的第一个输入,然后把一组参数作为它的下一个输入,以便在某个时候传递给那个函数。这就像预先设置这些参数,然后返回一个新函数 getCustomer。即它允许每次调用时用它来预设一个或多个输入,并返回一个所有其余输入的函数。从上面的代码我们可以看出要生成 getCurrentUser 函数就必须调用两次 partial 函数。
第二种是应用更加普遍的柯里化,它与偏函数虽然都实现了相同的功能,但它们的实现方式具有很大的不同。
function ajax(url) {
return function getData(data) {
return function getCB(cb) {
/*..*/
}
}
}
ajax(CUSTOMER_API)({
id: 2
})(renderCustomer);
var getCustomer = ajax(CUSTOMER_API);
var getCurrentUser = getCurrentUser({
id: 2
});
getCustomer({
id: 2
})(renderCustomer);
getCurrentUser(renderCustomer);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
这是一个手写的柯里化函数,他有三个嵌套的函数,每次调用都会返回一个函数,他可以将多元函数转换为一元函数,所有的函数库也有类似的工具,同时注释的是箭头函数的写法:
// var ajax = url => data => cb => { /*..*/ };
// var ajax = url => (data => (cb => { /*..*/ }));
var ajax = curry(
3,
function ajax(url, data, cb) {
/*..*/
}
);
var getCustomer = ajax(CUSTOMER_API);
var getCurrentUser = getCurrentUser({
id: 2
});
2
3
4
5
6
7
8
9
10
11
12
13
14
其中箭头函数的写法中我们建议使用第二行的写法,这样的可读性更好。函数库中的 curry 函数接收一个参数, 来告诉需要函数需要多少输入,第二个函数不需要我们进行处理,它只是一个普通的函数,接收的参数是 curry 函数设置的第一个参数。curry 函数会将其自动展开为一个对象,每次只接受一个输入,然后将所有输入用来调用传递的函数。
偏函数和柯里化的对比
- 两者都是使广义函数到特定函数的技术
- 偏函数可以预设一些参数,然后在下一次调用时接收剩余参数。
- 柯里化不会预设参数,只是在每次调用时接收每个参数。
var ajax = curry(
3,
function ajax(url, data, cb) {
/*..*/
}
);
// strict currying
ajax(CUSTOMER_API)({
id: 2
})(renderCustomer);
// loose currying
ajax(CUSTOMER_API, {
id: 2
})(renderCustomer);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
loose currying: 每次调用可以接受一个或者多个参数
strict currying: 每次调用只能接受一个参数
所有的 JS 函数库都是 loose currying 而不是 strict currying ,这是出于方便的考虑。
通过柯里化改变函数的“形状”
如下所示我们使用 map 函数来使得数组里面的所有元素增加1:
function add(x, y) {
return x + y;
}
[0, 1, 2, 3, 4].map(function addOne(v) {
return add(1, v);
});
// [ 1, 2, 3, 4, 5 ]
2
3
4
5
6
7
8
这里我们传入的是 addOne 函数,而不是 add 函数,这是由于 map 函数使数组的每个元素都会调用一次传递的函数,只有一个输入,因此其希望的是一元函数,而 add 函数具有两个输入是一个二元函数。两个根本的差别在于函数的“形状”不同,并且预输入一个参数使其特定化,从而改变函数的“形状”,更加专业的做法是使用柯里化:
add = curry(add);
[0, 1, 2, 3, 4].map(add(1));
2
注意:这里的 curry 函数是 JS 函数库中,这里编写 curry 函数。
# 组件 composition
一个函数调用后的输出成为下一个函数的参数的方法,在数学上称之为 Composition
这里我们有一系列函数,最后要计算总消费:
function minus2(x) {
return x - 2;
}
function triple(x) {
return x * 3;
}
function increment(x) {
return x + 1;
}
// add shipping rate
var tmp = increment(4);
tmp = triple(tmp);
totalCost = basePrice + minus2(tmp);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
上述过程就像一个生产糖果的工厂,由原材料到最后的糖果需要三道工艺。
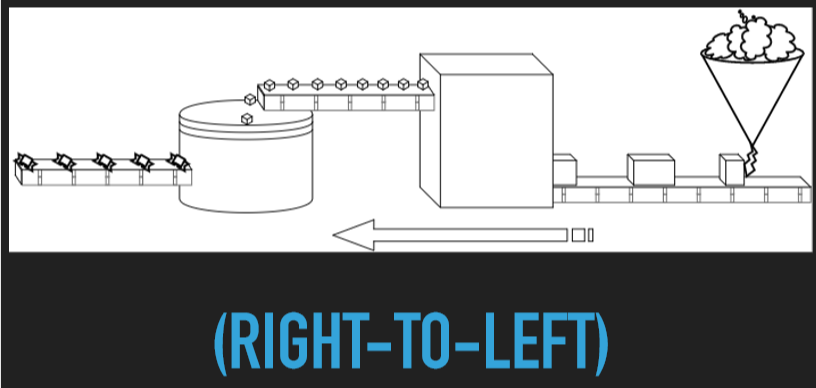
突然有一天,老板说其他糖果工厂生产速度非常快,我们这样速度太慢了,你必须要一个方法拉力提高生产速度,否则就要被淘汰了,于是你苦思冥想想到了一个方法,就是将中间传送带砍掉,传送的时间太长了,使得原材料一出来就降落到切割器中,切割之后降落到包装器中,从而及其占用的面积小了,相同的面积,又可以有更多的工艺装置了。
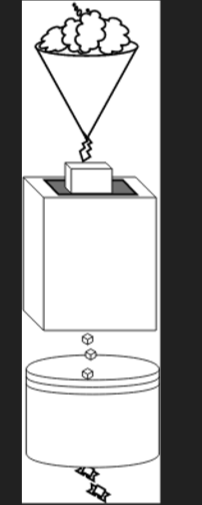
在上面的函数中就是将中间变量去除:
function minus2(x) {
return x - 2;
}
function triple(x) {
return x * 3;
}
function increment(x) {
return x + 1;
}
// add shipping rate
totalCost =
basePrice +
minus2(triple(increment(4)));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
就这样过了一阵,你的老板又找到你说工人开始抱怨装置太多,中间的操作按钮太多了,很容易搞混。于是你又开始思考,如何将其整合一个整体,从而工人们只需要操作输入和输出就行。
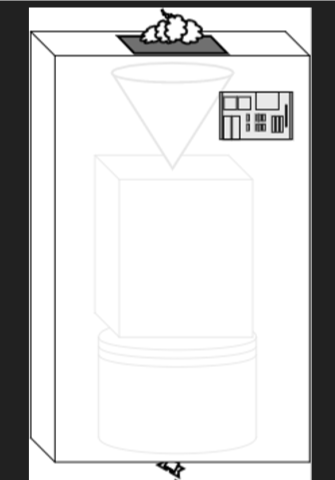
在上面的函数就是将中间步骤整合到同一个函数,从而代码更具声明性:
function shippingRate(v) {
return minus2(triple(increment(v)))
}
// add shipping rate
totalCost = basePrice + shippingRate(4);
2
3
4
5
6
这样相安无事一阵之后,你的老板急匆匆的找上你说,别的糖果厂今天可以生产这种口味的糖果,明天可以生产其他口味的糖果,并且不停产,你也要搞一个这种可以改变口味的机器出来,于是你设计了一个装置,能够接收单个小装置,从而产出一个大装置。
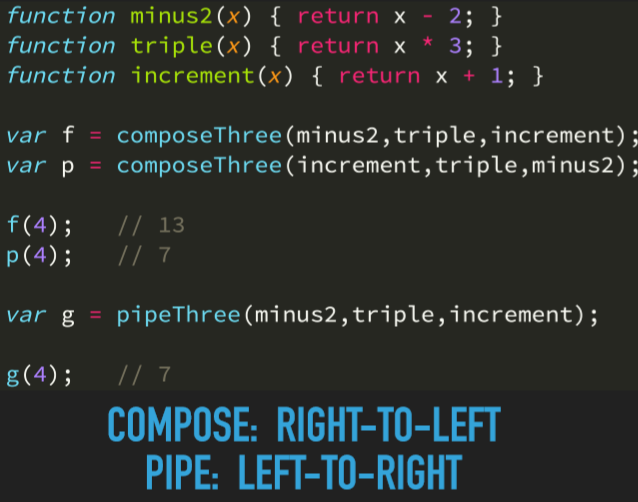
用上面的代码改造如下所示:
function minus2(x) { return x - 2; }
function triple(x) { return x * 3; }
function increment(x) { return x + 1; }
function composeThree(fn3, fn2, fn1) {
return function composed(v) {
return fn3(fn2(fn1(v)));
}
}
var shippingRate = composeThree(minus2, triple, increment);
// add shipping rate
totalCost = basePrice + shippingRate(4);
2
3
4
5
6
7
8
9
10
11
12
上面的 compseThree 具有声明式的数据流,且在函数库中其名称叫做 compose,可以任意多的函数进行组合。
上述函数的代码是 fn3(fn2(fn1(v))) ,因为 JS 函数执行是会先计算函数传递的参数,然后再执行函数内部的代码,即调用函数。
compose 函数的执行是从右到左,实际上指由内到外,而 pipe 函数执行是由左到右的
结合律
compose 是符合数学中的结合律的:
function minus2(x) {
return x - 2;
}
function triple(x) {
return x * 3;
}
function increment(x) {
return x + 1;
}
function composeTwo(fn2, fn1) {
return function composed(v) {
return fn2(fn1(v));
}
}
var f = composeTwo(composeTwo(minus2, triple), increment);
var p = composeTwo(minus2, composeTwo(triple, increment));
f(4); // 13
p(4); // 13
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
柯里化和“组件”结合
因为“组件”将函数的输出作为下一个函数的输入,因此组件中的函数必须都是一元函数,而柯里化的作用恰恰就是将多元函数转化为一元函数,因此两者可以结合起来使用,以解决多种问题。
function sum(x, y) {
return x + y;
}
function triple(x) {
return x * 3;
}
function divBy(x, y) {
return y / x;
}
divBy(2, triple(sum(3, 5))); // 12
sum = curry(2, sum);
divBy = curry(2, divBy);
composeThree(
divBy(2),
triple,
sum(3)
)(5);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 不变性 immutability
赋值不变性
即给一个变量赋值过后,无法再一次进行赋值,const 声明的变量即如此,无法再一次进行赋值,而不是代表这个值是不变的。
值的不变性
类似 string 和 number 类型的数据就是不可变的,而对象和数组声明之后其内部是可以变化的。因此我们需要遵循以下两种原则:
- 当我们调用函数并需要传递类似可变的数据如对象或者数组时,我们要通过使用
Object.freeze来冻结参数,确保其是一个只读数据。 - 如果我们在函数内部需要改变传递参数的状态,无论在何种情况我们都需要认为参数是只读的。
Read-Only Data Structures: Data Structures that never need to be mutated.
Treat all data structures as read-only whether they are or not.
{
let orderDetails = {
orderId: 42,
total: (basePrice + shipping)
};
if (orderItems.length > 0) {
orderDetails.items = orderItems;
}
// 确保参数是只读数据
processOrder(Object.freeze(orderDetails));
}
2
3
4
5
6
7
8
9
10
11
函数中如果需要给参数中添加状态,那么需要将参数进行复制后进行添加。
function processOrder(order) {
var processedOrder = {
...order
};
if (!("status" in order)) {
processedOrder.status = 'complete';
}
saveToDataBase(processedOrder);
}
2
3
4
5
6
7
8
9
数据结构不变性
Immutable Data Structures: Data structures that need to be mutated.
上述进行数据修改时,需要进行复制之后在进行属性的增加,当有成百上千次的修改该数据时,最坏的情况是最后的数据都需要进行垃圾回收,那么这对 CPU 也是很大的消耗。
针对以上问题我们需要一个不可变的数据结构,他不是在数据添加属性时创建一个全新的数据,而是通过改变内部指针一样指向前一个,有点类似 git 提交后的指针,每次提交代码,只是存储了与之前相比的不同之处。不可变数据结构在概念上本质上类似于获取t数据结构,其中创建的每个新对象在链中的都是前一个对象的不同之处。
它在内部存储着类似一个新的属性或者一个属性被改变了的东西。因此,CPU的性能损失和垃圾收集损失都是可以忽略的。
最常见的不变的数据结构的函数库是 immutable-js (opens new window)
var items = Immutable.list.of(
textbook,
supplies
);
var updateItems = items.push(calculator);
items === updateItems; // false
items.size; // 2
updateItems.size; // 3
2
3
4
5
6
7
8
9
10
11
# 递归 recursion
函数直接或者间接调用自身的函数称之为递归。
有时候有的问题可以使用递归函数,有的时候却是必须使用递归函数。程序员的主要工作不是让代码工作,而是要理解问题。
递归的三要素
第一要素: **明确你这个函数想要干什么。**确定函数的功能是什么,要解决什么问题。
第二要素: **寻找递归结束条件。**我们需要找出当参数为啥时,递归结束,之后直接把结果返回,请注意,这个时候我们必须能根据这个参数的值,能够直接知道函数的结果是什么。
第三要素: **找出函数的等价关系式。**我们要不断缩小参数的范围,缩小之后,我们可以通过一些辅助的变量或者操作,使原函数的结果不变。
function isVowel(char) {
return ['a', 'e', 'i', 'o', 'u'].includes(char);
}
function countVowels(str) {
var count = 0;
for (let i = 0; i < str.lengt; i++) {
if (isVowel(str[i])) {
count++;
}
}
return count;
}
countVowels(
'The quick brown for jumps over the lazy dog'
) // 11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这里的函数是使用 for 循环来实现的,这里我们将其改造为递归函数,首先确定其递归的结束条件,然后编写剩余代码:
function countVowels(str) {
if (str.length == 0) return 0;
var first = (isVowel(str[0]) ? 1 : 0);
return first + countVowels(str.slice(1));
}
countVowels(
'The quick brown for jumps over the lazy dog'
) // 11
2
3
4
5
6
7
8
其中 for 循环属于命令式编程,而递归函数更像是声明式编程。它更加注重结果,而不是执行过程。
递归结束条件的位置
上述递归结束的条件在第一行,如果我们的字符串只有一个字符,仍会调用两次函数,因此我们需要先进行第一个变量的计算,然后再进行递归条件的判断。实际上,就是递归结束条件的小小调整,也是递归函数的优化。
function countVowels(str) {
var first = (isVowel(str[0]) ? 1 : 0);
if (str.length <= 1) return first;
return first + countVowels(str.slice(1));
}
countVowels(
'The quick brown for jumps over the lazy dog'
) // 11
2
3
4
5
6
7
8
堆栈帧和内存限制
在很多情况下,一些人认为递归函数经常会导致内存不足引发栈溢出异常。因此有些人不会在实际应用中使用递归函数。
我们不要从计算机科学的角度来思考内存中的问题,如果我们考虑普遍的问题,当一个函数 A 运行时调用另一个函数 B 时,A 所发生的事情需要以某种方式保存,从而使得 B 函数得以正常调用。**即每一次执行函数,都会保留一块内存区域,在计算机术语中,我们称其为堆栈帧。**因此当一个函数调用另一个函数,然后另一个函数调用另一个函数,如此反复,我们得到的是一个不断增长的堆栈。只有最上面的函数执行完毕,然后出栈,才会调用下层的函数,如果我们的递归函数没有在正确的条件下返回,那么就会导致内存不足从而引起栈溢出。
递归优化:尾递归
尾递归就是从最后开始计算, 每递归一次就算出相应的结果, 也就是说, 函数调用出现在调用者函数的尾部, 因为是尾部, 所以根本没有必要去保存任何局部变量。直接让被调用的函数返回时越过调用者, 返回到调用者的调用者去。
总体思想是在任何给定的时间,基本上只需要一个堆栈帧,这是一个更大意义上的优化吗,而不仅仅指性能优化,因为在某些情况下,它实际上的运行速度要更慢,但它优化了内存使用。
ES6 使得我们可以标准化使用 JavaScript 引擎进行尾部递归,具体来说我们称它们为适当的尾部调用,PTC (proper tail calls)。前提条件是必须使用严格模式。
PTC 与 TCO ( tail call optimization ) 不同,TCO 尾部递归调用优化 是在 PTC 之上的一系列可选的潜在优化,引擎可以决定它想做什么。
proper tail calls are the idea that a tail call gets memory optimized, that we only use 0(1) memory space essentially.
PTC 是指尾部调用优化了内存,我们只使用0(1)内存空间。
尾部递归调用要求函数调用在尾部,并且除了返回调用的函数,不会进行其他运算,因此上面的例子可以修改成如下形式:
'use strict'
function countVowels(count, str) {
count += (isVowel(str[0]) ? 1 : 0);
if (str.length <= 1) return count;
return countVowels(count, str.slice(1));
}
countVowels(
0,
'The quick brown for jumps over the lazy dog'
) // 11
2
3
4
5
6
7
8
9
10
11
但上面会让用户指定初始值 0 ,这就将我们代码中的尾部递归的方式呈现出来,因此我们需要一种更干净的方式,只传递字符串参数,这就是函数式编程的方式,我们将其储存在闭包中,然后其他调用此函数的人只需要传递第二个参数就行了,这是我们使用柯里化的另一个例子:
'use strict'
function countVowels(count, str) {
count += (isVowel(str[0]) ? 1 : 0);
if (str.length <= 1) return count;
return countVowels(count, str.slice(1));
}
var countVowels = curry(2, countVowels)(0);
countVowels(
'The quick brown for jumps over the lazy dog'
) // 11
2
3
4
5
6
7
8
9
10
11
12
Trampolines (推荐的递归方法)
在了解 Trampolines 之前,我们先了解 Continuation-Passing Style(CPS),他的本质是一个回调函数,例如我们将上述的代码,修改为 CPS 风格:
function countVowels(str, cont = v => v) {
var first = (isVowel(str[0]) ? 1 : 0);
if (str.length <= 1) {
return cont(first);
}
return countVowels(str.slice(1), function f(v) {
return cont(frist + v);
})
}
countVowels(
'The quick brown for jumps over the lazy dog'
) // 11
2
3
4
5
6
7
8
9
10
11
12
我们实际上推迟了真正的递归调用,在 return cont(frist + v); 这行代码中,我们通过创建一个越来越大的函数来推迟每一步。
这在某种程度上是对范围误差问题的欺骗。但它实际上并没有解决内存问题。因为每次我们创建一个新函数时,我们都必须保留一个新的内存区域,而不是离开堆栈,而是离开堆。那是从堆中动态生成的东西不是从栈中生成的内存区域。
所以我们实际上并没有在这里增加堆栈。但是我们正在增加堆的使用。这意味着,如果你要运行一个cps风格的程序,理论上,你最终会耗尽整个系统的所有内存,它会崩溃。而且JavaScript在检查堆耗尽时不会报错。
因此我们需要使用 Trampolines
// 简写版本,类似Lodash Lambda等函数库都有类似的函数
function trampoline(fn) {
return function trampolined(...args) {
var result = fn(...args);
while (typeof result == 'function') {
result = result();
}
return result;
};
}
var countVowels = trampoline(function countVowels(count, str) {
count += (isVowel(str[0]) ? 1 : 0);
if (str.length <= 1) {
return count;
}
return function f() {
return countVowels(count, str.slice(1));
}
})
countVowels = curry(2, countVowels)(0);
countVowels(
'The quick brown for jumps over the lazy dog'
) // 11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这里我们使用 trampoline 做的不是递归调用,而是返回一个函数来执行下一次调用。我们只是在做一个while循环。调用这个函数,得到一个函数,调用这个函数,得到一个函数,诸如此类。
它可以永远持续下去。因为堆栈帧永远不会用完,所以堆也永远不会用完,而且它每次只执行一个函数。这是一个有趣而独特的方法来解决尾部递归调用问题。我们解决尾部调用问题的方法就是从一开始就不使用堆栈。
我们在原来 PTC 版本的 countVowels 函数中增加了一个函数 f,这个函数工作的方式是因为闭包。因此,在短暂的一微秒内,暂时保留这些值,以便可以将它们返回到 trampoline 实用程序,弹出调用堆栈,然后立即重新调用它并重新开始。
因此,我们正在利用返回堆栈帧的地方存储信息,然后堆栈帧弹出。它就像一个蹦床,增加一个调用栈,然后弹出,如此反复。而 PTC 的方式是一直增加调用栈,直到递归结束条件的位置,然后直接返回到最底层的调用栈。
# LISTS
map 数据结构的转换
首先,我们应该知道,像 map、filter、reduce 等函数应该适用于任何形式的数据结构,只是在 JavaScript 中,使用数组非常方便。
先来看下函子在维基百科上的定义
在范畴论中,函子是范畴间的一类映射。函子也可以解释为小范畴内的映射。
这里提到的映射,就是两个数据结构之间保持关联结构的一种抽象过程实现,可以理解为对两个数据结构进行映射的过程。函数所要表达的也是一种关系映射过程,那么 函子(Functor) 和函数的映射有什么关系呢?
我们来看看 kyle 怎么定义的:
A functor is a value, and by value I mean could be a collection of values, it is a value over which those values in it can be mapped. So if we talk about an array since we know we can call dot map on an array, it's a functor.
You just need to think essentially that's a value that I can map an operation across, okay?
函子就是一个值,这个值可以是一个集合,集合里面的每一个值都可以调用 map 函数就像数组可以使用map函数,因此数组就是一个函子。
你只需要知道函子是可以操作映射函数的值。
所以什么是映射(map)?简单来说就是数组结构之间的转换操作。
map 函数具有两个特点:
- map 函数的结果的数据结构与开始一致,如数组调用完 map 函数,其结果仍然是一个数组。
- map 函数生成一个转换后的值,但是数据结构不变,数据结构的“形状”不变
map 函数中的回调函数(mapper)应该只做一件事,如将数字转换为字符串,而不是进行条件判断,不同条件下进行不同的转换。
function uniqID() {
return Math.floor(Math.random() * 100);
}
function makeRecord(name) {
return {
id: uniqID(),
name
};
}
function map(mapper, arr) {
var newList = [];
for (let elem of arr) {
newList.push(mapper(elem));
}
return newList;
}
map(makeRecord, ['Kyle', 'Susan']);
// [ { id: 13, name: 'Kyle' }, { id: 95, name: 'Susan' } ]
// JS 中数组有内置的 map 函数
['Kyle', 'Susan'].map(makeRecord);
// [ { id: 68, name: 'Kyle' }, { id: 54, name: 'Susan' } ]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
filter: 包含
filter 函数是包含操作,而不是排除操作。当存在一个集合,其中的值被保留在结果中或被保留在结果之外时,建议使用 filter函数。
function isLoggedIn(user) {
return user.session != null;
}
function filterIn(predicate, arr) {
var newList = [];
for (let elem of arr) {
if (predicate(elem)) {
newList.push(elem);
}
}
return newList;
}
filterIn(isLoggedIn, [{
userID: 12,
session: 'adsf%sfdjk'
},
{
userID: 34
},
{
userID: 123,
session: 'daoi#hdakoo'
},
]);
// [
// { userID: 12, session: 'adsf%sfdjk' },
// { userID: 123, session: 'daoi#hdakoo' }
// ]
[{
userID: 12,
session: 'adsf%sfdjk'
},
{
userID: 34
},
{
userID: 123,
session: 'daoi#hdakoo'
},
].filter(isLoggedIn);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
reduce: 结合
reduce 函数是一个组合操作,从一个初始值开始,然后使用一个二元函数(reducer)对集合中的每一个元素进行操作,最终计算为一个值。
事实上,在不是 JS 的其他函数式编程语言中,filter 函数和 map 函数可以在一个大的数据结构中并行操作,凡是 reduce 函数并不可以,因为 reduce 函数根据当前累加器运行的值,来进行下一次的计算。
function addToRecord(record, [key, value]) {
return {
...record,
[key]: value
};
}
function reduce(reducer, initialVal, arr) {
var ret = initialVal;
for (let elem of arr) {
ret = reducer(ret, elem);
}
return ret;
}
reduce(addToRecord, {}, [
['name', 'kyle'],
['age', 39],
['isTeacher', true]
]);
// { name: 'kyle', age: 39, isTeacher: true }
[
['name', 'kyle'],
['age', 39],
['isTeacher', true]
].reduce(addToRecord, {});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
通过 reduce 实现 composition
reduce 函数在调用时,数组中的每个值(从左到右)开始缩减,而 reduceRight 函数是从右到左开始缩减。
function addOne(x) {
return x + 1;
}
function mul2(x) {
return x * 2;
}
function div3(x) {
return x / 3;
}
function composTwo(fn2, fn1) {
return function composed(v) {
return fn2(fn1(v));
}
}
var f = [div3, mul2, addOne].reduce(composTwo);
var p = [addOne, mul2, div3].reduceRight(composTwo);
f(8); // 6
p(8); // 6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
因此我们可以通过 reduce 实现 composTwo,而不是通过 for 循环等来实现,同时我们可以通过 reduceRight 来实现 pipe。
我们这里可以直接通过 reduceRight 来实现通用的 compose 函数:
function compose(...fns) {
return function composed(v) {
return fns.reduceRight(function invoke(val, fn) {
return fn(val)
}, v);
};
}
var c = compose(div3, mul2, addOne);
console.log(c(8)); // 6
2
3
4
5
6
7
8
9
同时我们也可以实现 pipe 函数:
function pipe(...fns) {
return function piped(v) {
return fns.reduce(function invoke(val, fn) {
return fn(val);
}, v);
};
}
var p = pipe(addOne, mul2, div3);
console.log(p(8)); // 6
2
3
4
5
6
7
8
9
10
融合
如果我们有一个 map 函数链,composition 是一个更好的方式来声明这些步骤是什么。
function mul2(x) {
return x * 2;
}
function div3(x) {
return x / 3;
}
var list = [2, 5, 8, 11, 14, 17, 20];
list.map(add1)
.map(mul2)
.map(div3);
// [2,4,6,8,10,12];
list.map(
compose(div3, mul2, add1)
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
但是函数式编程并不喜欢在值上调用方法,因为从更广阔的角度上来讲这属于面向对象的思维。而且在数组上面调用 map 函数不是纯函数调用,它接收的是数组上下文的隐式输入,并且在本质上这些函数是不可组合的,因为map调用的输入部分是间接的。所以我最终不得不创建一个变通的版本来组合这些函数。
所以像 Ramda 或者 Lodash 函数库,并不会直接使用数组内置的 map 方法,而是一个独立的 map 函数,它接收 mapper 函数和一个 数组,而不是将数组作为隐式输入。这使得函数更易柯里化和更易组合,因此我们应该使用这些函数库而不是内置的函数。
# 转换(transduction)
所以通过上面的例子我们将三个 map 函数通过 compose 结合在了一起,因为它们函数的“形状”通过函数式推理是可结合的,我们知道其内部是可以转化的,从而可以 compose 结合在一起。
如果我们向将 map、filter 和 reduce 函数结合在一起怎么办? 解决上面的问题是通过转换(transduction)。
它将上面所讲的知识点都融合在了一起,因此它是一个更加复杂的知识点。因此以下的论述可能存在错误,并且通过代码展示如何一步步实现 transduction,你不必完全理解其内部机制,只要会用即可。
你可能会在某些函数库的文档中看到过 transduce 的 API 接口,从而让你能够使用 transuction。 本质上如果你需要将 map、filter 或者 reduce 函数结合使用,那么你应该使用 transduction 。
我们知道 mapper、filterer 和 reducer 函数(这里指函数中的回调函数)拥有不同的函数“形状”。map 和 filter 函数“形状”不能组合是因为 map 函数接收单个参数,然后单个返回,filter 函数接收单个参数,返回布尔值。这是不同映射关系。同时你不能将其中的任意一个函数与 reduce 函数 compose 结合在一起,因为 reduce 函数接收两个参数。
function add1(v) {
return v + 1;
}
function isOdd(v) {
return v % 2 == 1;
}
function sum(total, v) {
return total + v;
}
var list = [1, 3, 4, 6, 9, 12, 13, 16, 21];
list.map(add1)
.filter(isOdd)
.reduce(sum);
// 42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
例如在上面一个场景我们有 map、filter 和 reduce 函数。但我们并不关心其函数本身,我们更关心的是 add1、isOdd 和 sum 函数,因为他们“形状”不可结合,但我们想将其 compose 结合在一起。
换句话说,transduction 是将 reducer 结合在一起。我们并不是想将 mapper、filterer 和 reducer 函数结合在一起,我们要做的是将 mapper 和 filterer 函数转换为 reducer函数,然后通过数学变化将其 compose 结合在一起。
你也可以像下面这样将所有的功能写进 reduce 函数中,但是这就变成了命令式编程,而不是函数式编程。
function add1(v) {
return v + 1;
}
function isOdd(v) {
return v % 2 == 1;
}
function sum(total, v) {
return total + v;
}
var list = [1, 3, 4, 6, 9, 12, 13, 16, 21];
list.reduce(function allAtOne(total, v) {
v = add1(v);
if (isOdd(v)) {
total = sum(total, v);
}
return total;
}, 0)
// 42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
因此我们需要一个声明式的解决方法,这就是 transducing 所做的事情。下面的代码演示了 transducer 如何工作。这里的 compose 函数与之前所讲的 compose 函数相同。
function add1(v) {
return v + 1;
}
function isOdd(v) {
return v % 2 == 1;
}
function sum(total, v) {
return total + v;
}
var transducer = compose(
mapReducer(add1),
filterReducer(isOdd)
);
transudce(
transducer,
num,
0,
[1, 3, 4, 6, 9, 12, 13, 16, 21]
);
// 42
into(transducer, 0, [1, 3, 4, 6, 9, 12, 13, 16, 21]);
// 42
[1, 3, 4, 6, 9, 12, 13, 16, 21].reduce(transducer(sum), 0);
// 42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
注意这里我们 compose 的并不是 add1 和 isOdd 函数,而是更加实用的两个函数工具 mapReducer 和 filterReducer 生成的函数。这些实用的函数工具在函数式编程的工具库中都可以找到。
所以你不用编写这些实用的函数工具,只需要使用即可。你只需要传递 mapper 函数和 filterer 函数即可。这些函数工具通过数学转化等将其函数“形状”转换为类似 reducer 的函数“形状”,但两者并不完全相同。
因为上述的 mapReducer 函数和 filterReducer 函数只是特殊的一种 redecer 函数,所以其需要通过 reducer 函数变成真正的 reducer 函数,就像这两个函数是 reducer 函数的原型状态一样。
因此,我们将那些具有原型“形状”的东西组合在一起。 这就是我们所说的 transducer(转换器)。具体而言,transducer 就是原型“形状”的生产者,可以通过 reducer 函数变成真正的 reducer 函数。transducer 是 reducer 的高阶函数。
但我没有直接将其添加到最终的 reducer 函数中,这是因为我们需要将所有的东西都添加到一个 reducer 函数中去,所以我们说 transducer 可以通过 reducer 函数变成真正的 reducer 函数。
函数库给我们提供了 transduce 函数,它接收四个参数,即我们生成的 tranducer 函数、连接符(combinator,在这里指 sum 函数)、一个初始值(0)和我们的数据结构(这里是数组),它在后台通过某种方式生成了一个新的 reducer 函数。然后,它使用新的 reducer函数缩小了数组。
transduce 函数实际上也只做了上述工作。因此,函数库还提供了另外一个函数 into 。 它只接收 tranducer 函数,初始值和数组三个参数。into 函数并不需要我们提供 reducer 函数。
因为 into 函数会根据初识值进行判断需要提供何种 combinator ,需要何种 reducer 函数。如果初始值是一个数字,它会自行判断需要对数字进行相加,这是数字的通用的 combinator,因此 into 函数会给我们提供一个类似 sum 的函数。
如果初识值是一个字符串,into 函数可能会提供一个字符串拼接的 combinator ,如果初始值是一个数组,into 函数可能会提供一个数组的 push 函数。
无论是 into 函数还是 tranduce 函数,都是同时进行了 map、filter 和 reduce 操作。
分解 trnasduction:提取reduce(Deriving Transduction: Extracting Reduce)
首先我们需要将最开始的 map 和 filter 函数改造成 reduce 操作,首先对他们进行 reduction 操作。使用 reduce 函数来进行 map 和 filter 操作的基本策略是,生成一个新的 list,然后在新的 list 中进行相关操作,所以这里 mapWithReduce 函数接收两个参数,一个是数组,一个是 mapper 函数。
最开始的状态:
function add1(v) {
return v + 1;
}
function isOdd(v) {
return v % 2 == 1;
}
function sum(total, v) {
return total + v;
}
var list = [1, 3, 4, 6, 9, 12, 13, 16, 21];
list.map(add1).filter(isOdd).reduce(sum); // 42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
将其变为 reducer 函数的状态:
function mapWithReducer(arr, mappingFn) {
return arr.reduce(function reducer(list, v) {
list.push(mappingFn(v));
return list;
}, []);
}
function filterWithReducer(arr, predicateFn) {
return arr.reduce(function reducer(list, v) {
if (predicateFn(v)) list.push(v);
return list;
}, []);
}
list = mapWithReducer(list, add1);
list = filterWithReducer(list, isOdd);
list.reduce(sum); //42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
注意上述代码的内部改变了函数传递的数组参数,因此他不是纯函数,存在副作用。但是我们在这里使用它的原因是 transduction 是性能优化,我们暂时允许其有点瑕疵。
但是上述代码中我们将其作为单独的函数进行调用而不是链式调用。同时如果我们将 mapWithReducer 函数和 filterWithReducer 函数里面的 reducer 函数分离出来,更加容易进行 compose 结合。
function mapWithReducer(mappingFn) {
return function reducer(list, v) {
list.push(mappingFn(v));
return list;
};
}
function filterWithReducer(predicateFn) {
return function reducer(list, v) {
if (predicateFn(v)) list.push(v);
return list;
};
}
list.reduce(mapWithReducer(add1), [])
.reduce(filterWithReducer(isOdd), [])
.reduce(sum); // 42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
分解 transduction:组合和柯里化(Deriving Transduction: Combiner & Currying)
从上面的代码中我们可以看到每个 reducer 函数非常相似,都是将一个值 push 到数组中,然后返回这个数组。上面的 if 语句,其实也是一个 mapper 函数。从抽象的角度上我们可以发现以下规律,接受数组中的一个值,然后缩小数组,并将这个值结合(combine)也就是添加到一个新的数组。
因此我们上面的步骤抽象出来,做成一个 combiner 然后在 reducer 函数中进行调用。
function listCombination(list, v) {
list.push(v);
return list;
}
function mapWithReducer(mappingFn) {
return function reducer(list, v) {
return listCombination(list, mappingFn(v));
};
}
function filterWithReducer(predicateFn) {
return function reducer(list, v) {
if (predicateFn(v)) return listCombination(list, v);
return list;
};
}
list.reduce(mapWithReducer(add1), [])
.reduce(filterWithReducer(isOdd), [])
.reduce(sum); // 42
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这里我们通过引用的方式来修改数组,但这从广义的角度来说是一个坏的方法。我们更希望通过参数的形式在 reducer 函数内部调用 combiner 函数。这里我们通过 curry 函数来实现:
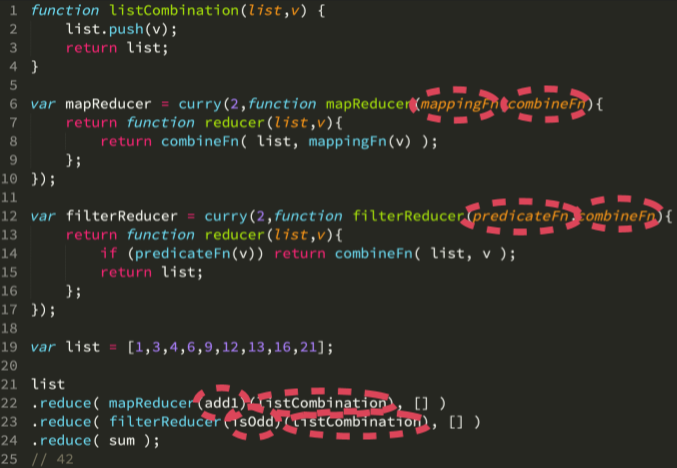
分解 trnasduction:单个 reduce(Deriving Transduction: Single Reduce)
但是到这里我们仍然使用了三个 reduce 函数,我们可以考虑将传递的 listCombination 函数抽象出来,就如同当初的 listCombination 函数一样。因此我们可以使用 compose 函数,并传递两个中间函数,这里并不是指 combination 函数。
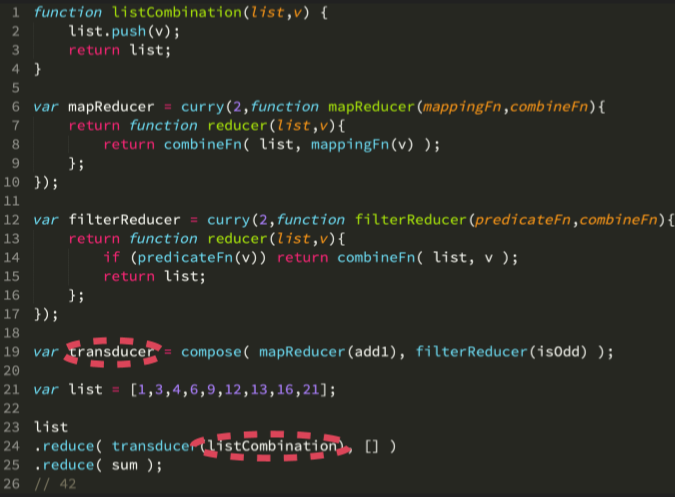
这里 mapReducer(add1) 生成了一个参数是 reducer 的函数,同样 filterReducer(isOdd) 也生成了这样的函数。当提供一个 reducer 函数时,他们就会生成一个 reducer 函数。如果讲一个 reducer 函数传递给高阶 reducer 函数 transducer,那么你会得到一个 reducer 函数。所以我们不在考虑在 composition 的过程中传递值,而是将 reducer 函数作为值在 composition 中传递,因此他们可以通过 compose 生成一个 transducer 函数。
listCombination 接收一个值和一个正在运行的累加器,它恰好是一个数组。它在累加器中添加传递进来的值。sum 函数是做什么的? 求和函数也是一样的,对吧?
sum 函数的同样接收一个值和一个累加器,把它们累加在一起的方法是做数字加法。sum 和 listCombination 实际上是相同的功能,因此上述两者同样可以结合:
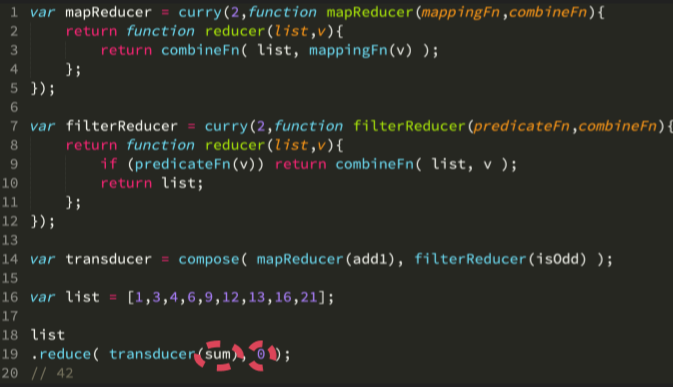
以上就是函数库中 transuder、transduce 和 into 函数后台所完成的功能,因此我们如果想用 transduction 可以直接使用函数库提供的方法。
# 数据结构
我们之前所讲的概念都是通过数组来演示,但是我们希望将上述所讲的函数式的概念融会贯通,运用到所有的数据结构中。
这里我们首先来编写对象的 map、filter 和 reduce 函数。
var obj = {
name: "Kyle",
email: "Getify@Gmail.com"
};
function objMap(mapper, o) {
var newObj = {};
for (let key of Object.keys(o)) {
newObj[key] = mapper(o[key]);
}
return newObj;
}
objMap(function lower(val) {
return val.toLowerCase();
}, obj);
// { name: 'kyle', email: 'getify@gmail.com' }
"use strict";
// inception!
curry = curry(2, curry);
var nums = {
first: [3, 5, 2, 4, 9, 1, 12, 3],
second: [5, 7, 7, 9, 10, 4, 2],
third: [1, 1, 3, 2]
};
var filteredNums = filterObj(function(list) {
return isOdd(listSum(list));
}, nums);
// point-free
pipe(
curry(2)(filterObj)(compose(isOdd, listSum)),
curry(2)(mapObj)(listProduct),
curry(3)(reduceObj)(sum)(0)
)(nums);
[
curry(2)(filterObj)(compose(isOdd, listSum)),
curry(2)(mapObj)(listProduct),
curry(3)(reduceObj)(sum)(0)
].reduce(binary(pipe))(nums)
var filteredNumsProducts = mapObj(function(list) {
return listProduct(list);
}, filteredNums);
reduceObj(function(acc, v) {
return acc + v;
}, 0, filteredNumsProducts);
// 38886
// ************************************
function mapObj(mapperFn, o) {
var newObj = {};
var keys = Object.keys(o);
for (let key of keys) {
newObj[key] = mapperFn(o[key]);
}
return newObj;
}
function filterObj(predicateFn, o) {
// TODO
var newObj = {};
var keys = Object.keys(o);
for (let key of keys) {
if (predicateFn(o[key])) {
newObj[key] = o[key];
}
}
return newObj;
}
function reduceObj(reducerFn, initialValue, o) {
// TODO
for (let key of Object.keys(o)) {
return reducerFn(initialValue, o[key]);
}
}
// ************************************
function curry(arity, fn) {
return (function nextCurried(prevArgs) {
return function curried(nextArg) {
var args = prevArgs.concat([nextArg]);
if (args.length >= arity) {
return fn(...args);
} else {
return nextCurried(args);
}
};
})([]);
}
function compose(...fns) {
return function composed(arg) {
return fns.reduceRight((result, fn) => fn(result), arg);
};
}
// function compose(...fns) {
// return function composed(arg) {
// return fns.reduceRight(function reducer(result, fn) {
// return fn(result);
// }, arg);
// };
// }
function pipe(...fns) {
return compose(...fns.reverse());
}
function binary(fn) {
return function two(arg1, arg2) {
return fn(arg1, arg2);
};
}
// ************************************
function isOdd(v) {
return v % 2 == 1;
}
function sum(x, y) {
return x + y;
}
function mult(x, y) {
return x * y;
}
function listSum(list) {
return list.reduce(sum, 0);
}
function listProduct(list) {
return list.reduce(mult, 1);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
Monad
Monad 是一个包装器,使一个值可以有一些列行为,从而使这个值更容易与其他值相互操作。
Monad 的一个特点就是将一个值变为一个 funtor,但 Monad 并不只有这个作用。之前我们已经讲过 functor 就是一个可以进行 map 操作的对象。
A monad is just a monoid in the category of endofunctors —— Phillip Wadler
但上面用了一些我们并不熟悉的术语来解释 monad 是什么,因此 Kyle 给我们一个更易理解的定义。
It's just a pattern for pairing some piece of data with a set of predictable behaviors that let it interact with other pairings of data and behavior, in other words monads. —— Kyle Simpson
monad 就将一些数据(funtor)和方法组合应用的模式,从而可以与其他数据及方法(monad)进行相互操作。
它使用一系列技术使值在特定情况下更易操作,它是一种数学方法。在 JavaScript 这种非函数式编程语言中,我们需要自行来编写 monad,从而有多种方式可以编写 monad,可以有多种类型的 monad,而不像 Haskell 这种语言拥有特定的形式。
这里我们展示编写的 monad,但是平时我们可能更加喜欢使用函数库提供的 API。
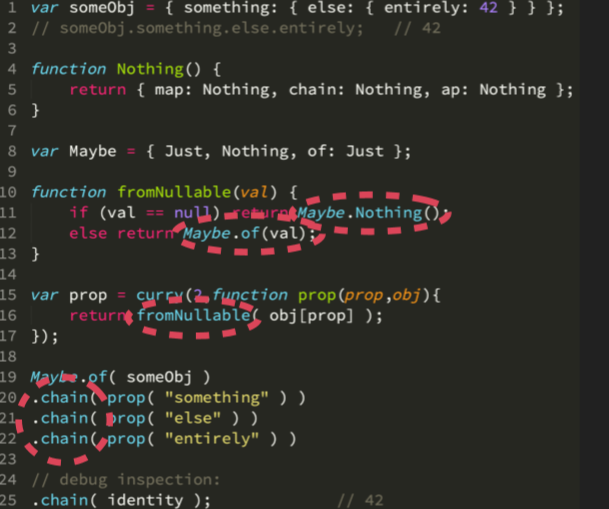
这里我们先编写最基本的 monad,名字就叫 Just,它只包装一个值,可能是对象、数组等等,但是从 monad 角度来看,这个值只是一个单独的实体,你需要做的可能就是将这个包装的单独的实体变成另一个包装的实体。
就像数组一样,每次我们调用 map 函数都会得到另外一个 数组,如果一个 monad 调用map 函数,你同样可以得到一个不同的 monad。因此,你可以看到 Just,即一个 monad,它有 map、chain 和 ap 方法。
function Just(val) {
return {
map,
chain,
ap
};
}
2
3
4
5
6
7
但是不同的 monad 具有更多不同的方法。但这三个核心方法是每个 monad 都必须有的。同时,chain 方法经常与其他名称一起被提及。所以我们来简单的编写这三个方法吧。
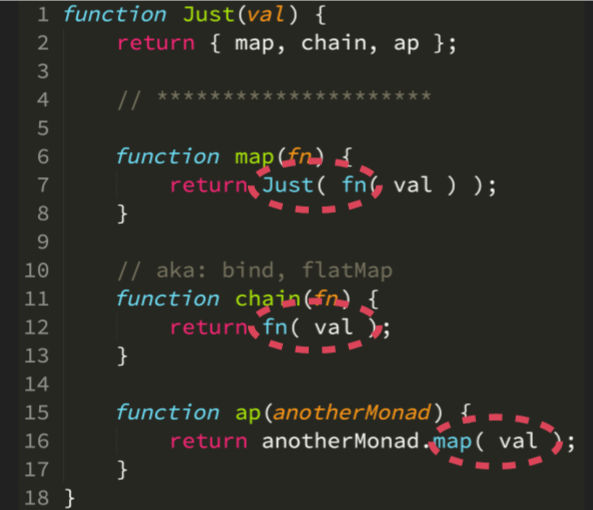
这里的 map 函数,可以看到第7行我们在函数调用的外面加上了 Just,就像一个数组调用 map 函数之后返回的同样是一个数组,就像这里 monad 调用 map 函数之后,同样返回同样类型的 monad。
其次是 chain 方法,这里只是简单描述了其观点,简化了其内部实现。在其他函数库的实现上,chain 方法通常是 bind 或者 flatMap 方法。
最后一个是 ap 方法,这个方法比较奇怪,因为它接收另外一个 monad,并通过 map 函数生成同样不同的 monad,但是这里要注意 map 方法应该接收 mapper 函数,也就是这里的 val 其实是一个函数,那么我们的 monad 里会有什么样的函数呢? 我们可能会有一个 curry 函数,里面有一些值,它会被用作另一个 monad 的映射。
下面主要展示了 Just Monad 的使用,以及另一种更加常见的 Maybe Monad。
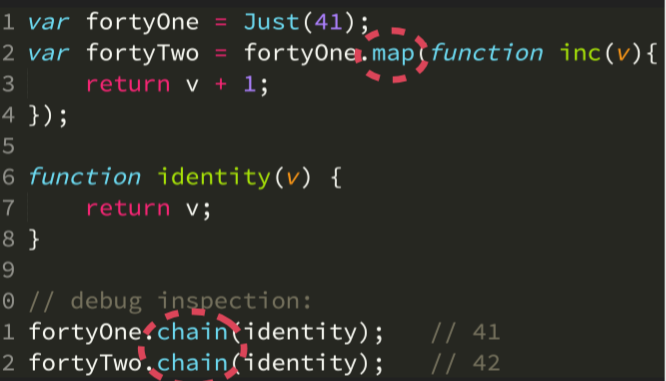
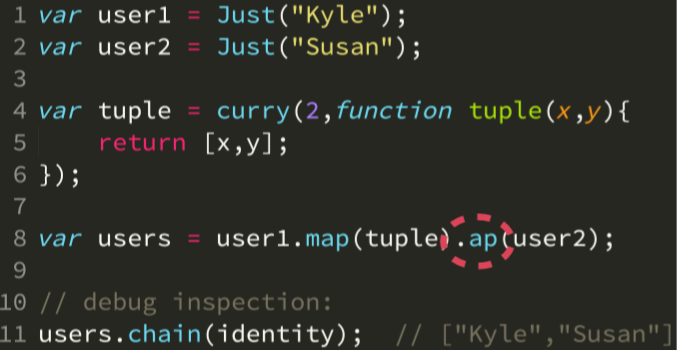

# 异步(Async)
到目前为止我们所学的函数式编程的知识点,都只用在了同步编程上,我们希望同样用于异步编程上。
例如,下面的例子就是 synchronous、eager FP。
var a = [1, 2, 3];
var b = a.map(function double(v) {
return v * 2;
})
console.log(b); // [ 2, 4, 6 ]
2
3
4
5
6
这里我们假想拥有一个 mapLazy 的函数,每当 a 数组添加一个值,就会执行 map 函数,然后 b 数组就会相应的发生变化。
var a = [];
var b = mapLazy(function double(v) {
return v * 2;
}, a);
a.push(1);
a[0]; //1
b[0]; // 2
a.push(2);
a[1]; // 2
b[1]; // 4
2
3
4
5
6
7
8
9
10
11
12
他可以解决当数据是异步时 map 函数的一系列问题,但 mapLazy 并不一定存在。同时如果我们有一个不是常规的数组,那么可能 mapLazy 并不适用,适用的是 lazyArray 了。
var a = new LazyArray();
setInterval(function everySecond() {
a.push(Math.random());
}, 1000);
// ********************
var b = a.map(function double(v) {
return v * 2;
});
a.forEach(function onValue(v) {
console.log(v);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
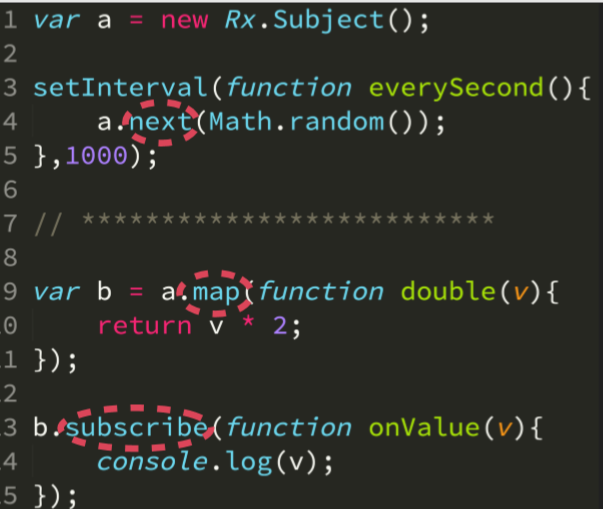
Observables
但是上面的 lazyArray 和 lazyMap 并不存在,但我们拥有 observable ,它类似于一个数据表,你设置单元格 B5 = A1 * 2 ,那么当你设置 A1 单元格的值为1时,B5 单元格的值会编程2,就像我们之前演示的 mapLazy 函数一样,如果其它单元格也设置了相应的关联,那么也会随着单元格 A1 的变化而变化。就像是一个异步的数据流。
常用的 observable 的函数库是 Rx.js,它使我们异步函数式编程更加方便。